")
Les utilisateurs de Qlik Sense peuvent aller chercher les données préparées pour l'analyse dans le catalogue de Data Catalyst. (Crédit : Qlik)
La solution de management de données de Podium Data, rachetée par Qlik, sort dans une version 4.0 rebaptisée Data Catalyst. Cette plateforme permet de préparer les données d'un datalake sous Hadoop pour les mettre ŕ disposition des utilisateurs métiers. Elle peut maintenant fonctionner aussi sur un serveur sous Linux pour les volumes moins importants.
Rachetée par Qlik ŕ l'été 2018, la technologie de gestion des données de Podium Data apporte ŕ l'éditeur de logiciels analytiques des fonctions de catalogage et de préparation automatisée des données, ŕ installer ŕ l'échelle de l'entreprise sur de grands volumes. Cette solution, qui permet de réduire le temps de mise ŕ disposition des données pour les utilisateurs métiers, est de męme nature que celles proposées par des éditeurs comme Datameer, Trifacta ou Waterline Data. Rebaptisée Data Catalyst par Qlik, qui vient d'en annoncer la version 4.0, elle donne accčs ŕ des données prętes ŕ ętre analysées ŕ travers un catalogue sécurisé. Elle s'utilise on-premise, dans le cloud, en mode hybride ou sur un modčle multi-cluster, ce qui laisse le choix aux entreprises de l'endroit oů se font le stockage, la préparation et l'accčs aux informations.
La plateforme de data management peut ętre déployée dans le cloud public d'AWS, dans celui de Google ou dans Azure de Microsoft. Elle inclut des fonctions de gouvernance de données et de gestion des métadonnées. Parmi les nouveautés de sa version 4.0, la connectivité ŕ Qlik Sense est fournie clé en main et la solution s'est adaptée au traitement de volumes de données moins importants. Jusqu'ŕ présent Data Catalyst nécessitait d'installer un cluster Hadoop (HDFS, Apache Hive). Désormais, il est possible de se contenter d'un serveur sous Linux (avec Linux FS et HyperSQL) pour le stockage et le traitement de volumes plus modestes.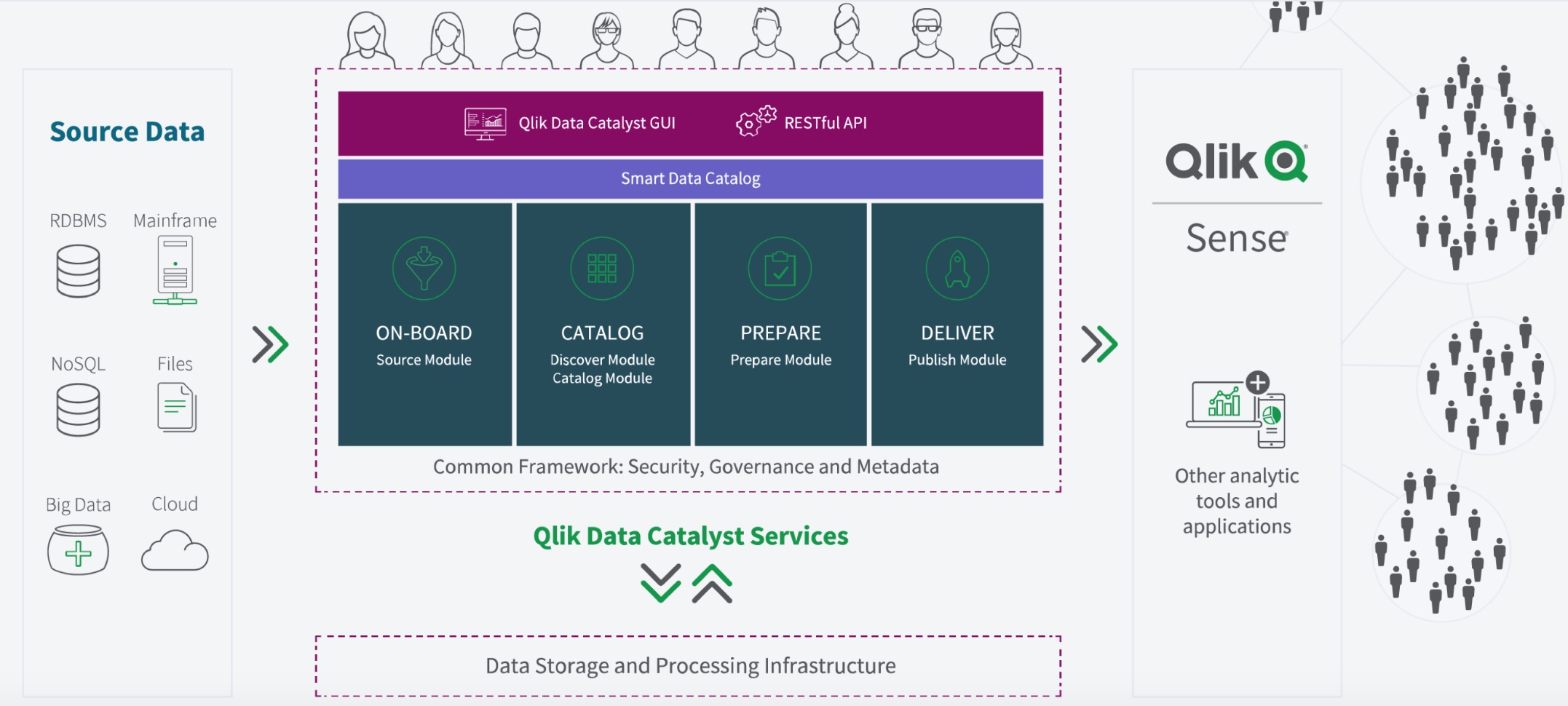
Les modules d'extraction, de découverte, de catalogage, de préparation et de publication de données de Data Catalyst reposent sur un framework commun apportant des fonctions de sécurité, de gouvernance et de gestion des métadonnées.
Lorsqu'elle est utilisée avec les services cloud d'AWS, la version 4.0 supporte de nouveaux scénarios. Lors de l'ingestion des données, elle peut continuer ŕ fonctionner si le cluster EMR (Elastic MapReduce) d'AWS tombe. Elle s'intčgre avec les environnements Redshift pour permettre de publier directement depuis Data Catalyst vers Redshift Spectrum (ce service permettant de requęter trčs rapidement des données - en mode parallčle - dans Amazon S3 sans avoir ŕ les charger dans les tables Redshift). L'utilisation d'un data lake on-premise peut ętre combiné avec des données publiées sur Redshift. Il est également possible de publier des données vers Athena, le service de requęte interactif d'AWS destiné ŕ faciliter l'analyse des données dans Amazon S3 ŕ partir d'une syntaxe SQL. Par ailleurs, la publication peut aussi se faire vers le datawarehouse Snowflake.
Davantage de mises en relation entre les données
Dans la version 4.0 de Data Catalyst, Qlik a par ailleurs étendu les capacités de mises en relation entre les données. On peut en importer ŕ partir de JDBC ou de catalogues externes et un nouveau moteur d'inférences permet de découvrir des relations non identifiées jusque-lŕ, au sein de chaque source de données ou ŕ travers des sources disparates. Lors de la préparation des données, des recommandations de relations sont suggérées. Au moment de l'utilisation, la transition se fait facilement entre l'accčs ŕ plusieurs datasets et leur analyse combinée.
L'intégration qui a été développée entre la solution de data management et le logiciel analytique Qlik Sense permet maintenant de passer instantanément de l'un ŕ l'autre. Pour visualiser les données, un assistant, Insight Advisor, crée automatiquement des représentations adaptées. Enfin, concernant les évolutions apportées ŕ l'expérience utilisateur dans la version 4.0, Qlik signale un processus d'installation plus simple et plus rapide, la possibilité de naviguer graphiquement dans la hiérarchie des dossiers, ainsi que la notification des tâches de longue durée qui se sont achevées. Dernier point, l'assistant de publication des données a été amélioré pour en simplifier le processus.










Suivez-nous