")
Pour David Kanter, MLPerf doit toujours faire évoluer ses benchmarks pour répondre aux besoins de l’industrie. (Crédit S.L.)
Avec 56 000 résultats collectés depuis son lancement, MLPerf s'impose comme un benchmark clef pour mesurer les performances des modčles d'apprentissage automatique. Sous l'égide de MLCommons, cette suite de benchmarks fait évoluer l'intelligence artificielle dans un cadre normatif.
En 2024, le secteur de l'intelligence artificielle a connu une croissance fulgurante, portée par l'adoption massive de modčles génératifs et par des besoins en calcul toujours plus importants. Dans ce contexte, MLPerf, un ensemble de benchmarks développé par le consortium MLCommons, s'est positionné comme le standard pour évaluer la performance et l'efficacité énergétique des systčmes d'IA. Pourtant, au-delŕ des chiffres et des classements, une question persiste : ces benchmarks reflčtent-ils véritablement les exigences des utilisateurs finaux ?
Des objectifs ambitieux pour une IA équitable et efficace
Lors d'un IT Press Tour fin janvier dans la Silicon Valley, David Kanter, directeur exécutif de MLCommons, nous a expliqué la mission de son organisation : « Nous cherchons ŕ rendre l'IA meilleure pour tous en améliorant la précision, la sécurité, la rapidité et l'efficacité énergétique. ». Pour atteindre cet objectif, MLPerf s'appuie sur une méthodologie standardisée qui combine des contributions de l'industrie IT et du monde académique. Chaque benchmark est conçu pour ętre reproductible, basé sur des charges de travail représentatives, et ouvert ŕ des solutions proches des usages métiers.
Depuis 2018, MLPerf a évolué pour couvrir des domaines variés, allant de l'entraînement des modčles ŕ l'inférence en passant par le stockage. Chaque cycle de benchmark attire de nouveaux acteurs, comme récemment Google et Nvidia au côté d'Azure, Dell, Cisco, Fujitsu, Lenovo, Oracle, Quanta, Supermicro... reflétant ainsi la compétitivité accrue dans le domaine.
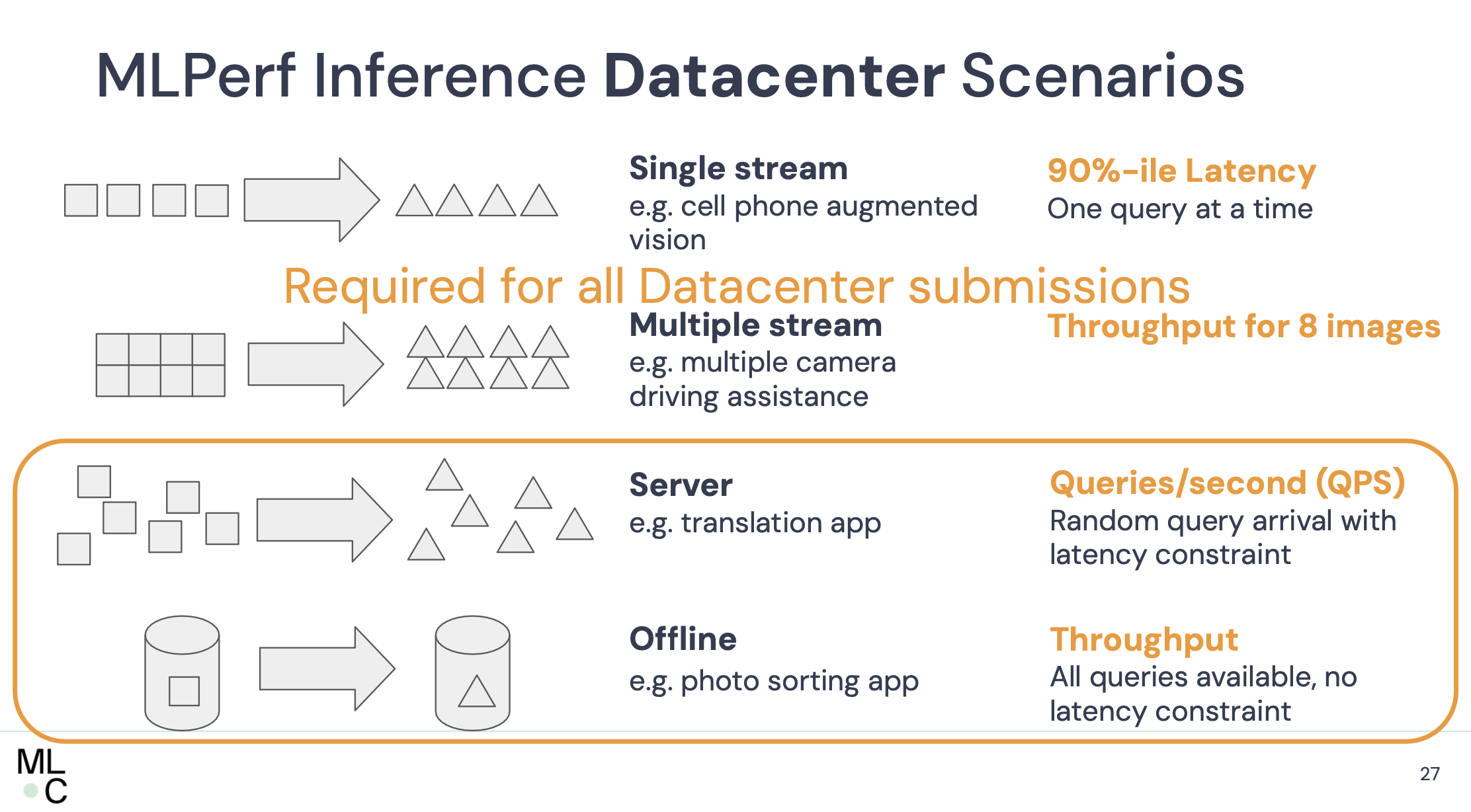
Plusieurs scénarios sont envisagés pour mieux tester les différentes plateformes IA. (Crédit S.L.)
Une méthodologie rigoureuse, mais adaptable
Les benchmarks MLPerf se déclinent en deux divisions : fermée et ouverte. Dans la division fermée, les modčles soumis doivent respecter des critčres stricts pour permettre une comparaison équitable entre différents matériels. La division ouverte, en revanche, autorise des modifications significatives, favorisant l'innovation et les nouvelles approches technologiques.
Un exemple emblématique est la mesure du temps d'entraînement, une approche introduite pour s'assurer que les solutions soumises atteignent un seuil minimal de précision. David Kanter souligne : « La rapidité n'a de sens que si elle s'accompagne d'une précision suffisante. Nous avons vu des techniques qui sacrifiaient la qualité pour des gains en performance. MLPerf évite cela en imposant un seuil de validité. »
L'importance de l'efficacité énergétique
Un autre aspect essentiel abordé par MLPerf est la consommation d'énergie. Selon M. Kanter, « dans un monde de plus en plus contraint par les ressources énergétiques, il est impératif que les solutions IA soient mesurées non seulement en termes de rapidité, mais aussi d'efficacité énergétique. Ce focus sur l'énergie répond ŕ des préoccupations croissantes concernant l'impact environnemental des centres de données de plus en plus énergivore. Malgré ses mérites, MLPerf n'échappe pas ŕ la critique. Certains experts pointent le risque de résultats biaisés. « La liberté laissée aux participants pour adapter leurs solutions aux benchmarks peut refléter des cas idéalisés plutôt que des scénarios réels », concčde David Kanter. Toutefois, il défend la transparence de l'approche : « Tous les résultats sont publiés sur GitHub, permettant ŕ quiconque de les reproduire ». En outre, le manque de participation de certains grands acteurs, comme Amazon Web Services, soulčve des questions sur la représentativité globale de MLPerf.










Suivez-nous