")
Alexei Grinbaum, directeur de recherche au CEA estime que le modčle R1 de Deepseek est en rupture sur deux points : son côté open source et la technique d'apprentissage par renforcement. (Crédit Photo : IT News Info)
Propulsée sur le devant de la scčne, la start-up chinoise Deepseek et son modčle de raisonnement R1 intriguent. Pourquoi un tel engouement ? Quelles sont les différences par rapport ŕ des modčles similaires ? Quelles infrastructures utilise-t-il ? Décryptage avec un expert de l'IA.
Encore inconnue il y a quelques semaines, la société chinoise Deepseek ŕ l'origine du modčle de raisonnement R1 est devenue en quelques jours un phénomčne en inquiétant les grands acteurs de l'IA. Son application de GenAI - également appelé Deepseek et reposant sur son LLM R1 - a pris la tęte des programmes les plus téléchargés sur l'App Store d'Apple. Plus performant, entraîné ŕ moindre coűt, open source, le LLM affiche ses avantages par rapport ŕ la concurrence. Pour en savoir plus, Alexei Grinbaum, directeur de recherche et président du comité opérationnel d'éthique du numérique du CEA nous donne son éclairage.
Une méthode d'apprentissage par renforcement plus ciblée
Pour lui, le LLM R1 de Deepsek « n'est pas révolutionnaire, mais il marque une étape sur deux points. Tout d'abord, c'est la premičre fois qu'un modčle de raisonnement est mis en open source et l'autre point réside dans la technique utilisée pour l'apprentissage par renforcement », observe-t-il. Sur la technique, il sépare « le modčle de fondation (Deepseek v3) et celui de raisonnement (R1). Sur le premier, la méthode d'apprentissage par renforcement « s'est faite sans annotations humaines ». Par contre, sur le second, l'apprentissage par renforcement a été supervisé par l'humain ». Une différence avec o1 d'OpenAI oů « la supervision humaine est présente sur les deux modčles ». A noter aussi un phénomčne inexpliqué baptisé le « moment aha », par les experts de Deepseek sur le modčle de fondation. « Il apprend ŕ consacrer plus de temps de réflexion ŕ un problčme en réévaluant son approche initiale », soulignent-ils dans leur document de travail.
En termes de benchmark, « le modčle de fondation derričre R1 n'est pas trčs bon par rapport ŕ o1 d'OpenAI, par contre son modčle de raisonnement est aussi performant », indique le chercheur. Pour lui la clé est ŕ chercher dans « le dataset qui a servi au modčle de fondation, il est trčs qualifié et il y a eu un grand travail en amont sur ce point. » Pour autant, impossible de savoir exactement ce que contient ce jeu de données « cette partie n'est pas open source », regrette-t-il. Alexei Grinbaum salue également « la qualité de l'algorithme utilisée. »
Une distillation plus efficace
Autre enseignement des travaux de Deepseek, « la distillation du modčle R1 en de plus petits modčles les rend plus efficace », explique Alexei Grinbaum. Pour lui « c'est une énorme découverte. Nous nous apercevons aujourd'hui que l'on peut reproduire le modčle doté de 671 milliards de paramčtres et le distiller dans des modčles de 7 ŕ 3 milliards de paramčtres plus performants que les SLM créent ŕ partir de zéro. »
Deepseek a présenté ses deux premiers SLM distillés : l'un basé sur le LM Qwen développé par Alibaba Cloud et l'autre sur Llama de Meta. Les chercheurs précisent qu'ils n'ont pas appliqué « d'affinage supervisé » ou « d'apprentissage par renforcement. » Les résultats poussés par les experts montrent des gains d'efficacité sur l'ensemble des tests face ŕ la concurrence. « Cela signifie que le modčle de raisonnement est réplicable sur des plus petits modčles et que cela fonctionne mieux pour certaines tâches », dit Alexei Grinbaum. Il constate une effervescence de la communauté open source sur Hugging Face depuis la sortie de R1, « des groupes travaillent justement sur cette réplication sur leur propre modčle. »
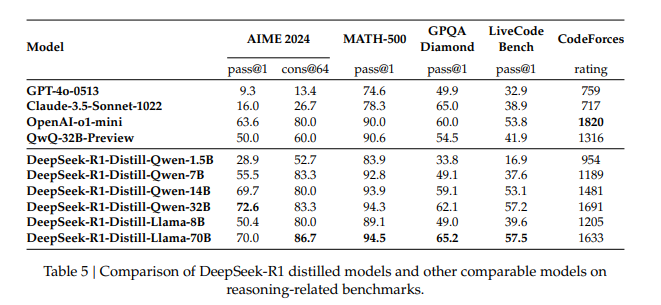
Les modčles distillés de DeepSeek affichent de meilleures performances par rapport ŕ la concurrence. (Crédit Photo : Deepseek)
Une infrastructure IA qui questionne
Outre les aspects algorithmiques, l'intéręt pour Deepseek porte sur l'utilisation d'une infrastructure IA "minimaliste" et un développement ŕ moindre coűt. D'aprčs la start-up, elle se sert d'un cluster de 2 048 GPU H800 de Nvidia. Ces puces ont été développées ŕ la fin 2023 par le fournisseur pour répondre ŕ la limitation américaine des exportations des puces avancées vers la Chine. Une infrastructure qui interroge plusieurs spécialistes. Jimmy Goodrich, conseiller auprčs de Rand Corp (société de conseil américaine auprčs du ministčre de la Défense) questionné par Reuters, indique « il existe au moins une douzaine de supercalculateurs majeurs en Chine équipés d'un nombre important de puces Nvidia dont l'achat était légal au moment oů DeepSeek les a utilisés pour apprendre ŕ devenir plus efficace. » Alexander Wang, CEO de Scale AI (spécialisé dans le développement d'applications ŕ base d'IA) est plus suspicieux, « les laboratoires chinois ont plus de H100 qu'on ne le pense » souligne-t-il dans une interview ŕ CNBC. Il ajoute « je crois savoir que DeepSeek possčde environ 50 000 H100, dont ils ne peuvent évidemment pas parler, car cela va ŕ l'encontre des contrôles ŕ l'exportation mis en place par les États-Unis. »
D'autres interrogations portent sur le coűt du modčle R1, estimé selon Deepseek ŕ 5,7 M$. Or la société n'a pas donné de détails sur la ventilation des coűts, laissant plusieurs observateurs penser que le montant total ne comprend pas certains éléments comme le nombre de GPU mobilisés pour la formation du modčle. Chez les concurrents OpenAI et Anthropic les montants dépensés pour l'entrainement des modčles atteint des sommes astronomiques, respectivement de 7 Md$ et de (2,7 Md$. Une chose est sűre cependant : « avec le travail en amont sur le dataset, le besoin en calcul est moindre », admet Alexei Grinbaum. Une efficience qui pourrait ainsi permettre ŕ l'éditeur chinois de ne pas avoir ŕ investir autant que ses concurrents dans l'entraînement et le développement de LLM. Notre confrčre d'IDG indique que Deepseek a amélioré l'efficacité de la bande passante de la mémoire grâce ŕ deux innovations clés: l'utilisation d'un algorithme optimisé (compression du cache clé-valeur) et le passage de FP32 (32 bits) ŕ FP8 (8 bits) pour l'entraînement ŕ la précision du modčle. La réduction de la mémoire requise permet d'entraîner des modčles plus volumineux et de réduire le temps d'entraînement.
Un rééquilibrage de la géopolitique de l'IA
L'aspect géopolitique de l'ascension de Deepseek n'est pas non plus ŕ négliger. La prédominance des américains a été écornée dans ce domaine. Marc Andressen, un des plus gros investisseurs dans l'IT aux Etats-Unis a qualifié cette arrivée de « moment spoutnick », en référence la découverte du satellite russe, qui a rebattu les cartes de la conquęte spatiale majoritairement dominée par les Etats-Unis. « Avec Deepseeck, la Chine rattrape son retard sur les américains avec une modčle plus optimisé et plus efficace », affirme Alexei Grinbaum.
Il s'attend ŕ ce que les grands acteurs IA américains ripostent « avec la présentation prochaine du modčle o3 d'OpenAI. » De son côté, la start-up chinoise va certainement améliorer son modčle de raisonnement R1 et en renforcer la sécurité. Ce lundi, la société a communiqué sur une cyberattaque « ŕ grande échelle » qui l'a forcée ŕ restreindre le nombre d'inscriptions.










Suivez-nous