")
Le cabinet ACF-S d'Enfabrica n'a pas encore de prix, ni de date de lanceument. (Crédit Enfabrica)
Selon la start-up californienne, les smartNIC étant conçus pour la communication de CPU ŕ CPU, ils sont moins optimaux pour la communication entre GPU.
La jeune pousse Enfabrica fait le tour des salons professionnels pour présenter ses produits de réseau spécifiquement destinés ŕ gérer le débit de données élevé requis par l'IA. La start-up affirme que son silicium Accelerated Compute Fabric SuperNIC (ACF-S) peut offrir une bande passante plus élevée, une plus grande résilience, une latence plus faible et un meilleur contrôle par programmation aux opérateurs de centres de données qui exploitent l'IA et le HPC ŕ forte intensité de données. L'entreprise, qui est sortie de son mode furtif l'année derničre, a annoncé un cycle de financement de 125 millions de dollars mené par Atreides Management avec le soutien de Nvidia ainsi que de plusieurs sociétés de capital-risque. Ŕ noter que Nvidia est également présente dans le secteur des smartNIC avec sa gamme BlueField. Enfabrica a été créée en 2020 par Shrijeet Mukherjee, auparavant responsable des plateformes et de l'architecture réseau chez Google, et par le CEO Rochan Sankar, ancien directeur de l'ingénierie chez Broadcom sur la base d'un constat : que le matériel de mise en réseau était construit sur des conceptions vieilles de 20 ans qui conviennent parfaitement aux CPU, mais pas aux réseaux GPU. « Si l'on regarde ce qui s'est passé avec le réseau des centres de données, il a évolué vers ce type de conception oů du trafic arrive d'une direction et l'on veut ętre capable de le partager et de le distribuer ŕ tout un tas de noeuds. Mais les systčmes d'IA et de ML ont un peu cassé le concept », a expliqué M. Mukherjee, désormais directeur du développement de la start-up.
Enfabrica soutient que dans les environnements de centres de données traditionnels, les modalités de mise en réseau des serveurs limitent la bande passante et la tolérance aux pannes. Dans un environnement d'IA, le déplacement des données entre les GPU nécessite plusieurs sauts, ce qui peut provoquer des congestions et entraîner une répartition imprévisible de la charge. Or, la défaillance d'une liaison GPU bloque l'ensemble du travail. « La conception des supercalculateurs actuels n'est pas trčs tolérante aux pannes, et il faut vraiment déployer beaucoup d'efforts pour gérer correctement les pannes », a fait remarquer M. Mukherjee.
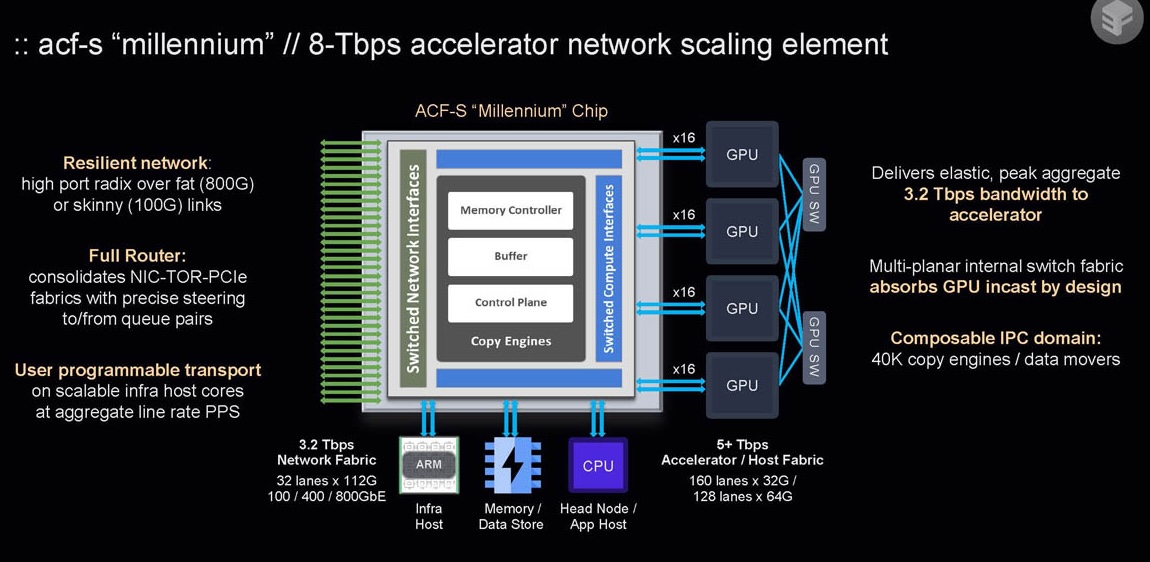
Le contrôleur ACF-S d'Enfabrica assure un lien entre les CPU, les GPU et la mémoire via le protocole CXL pour accélérer la circulation des données. (Crédit Enfabrica)
Enfabrica apporte la tolérance aux pannes ŕ la conception des réseaux. Au lieu de faire du point ŕ point, plusieurs chemins d'accčs sont possibles d'un point ŕ un autre, ce qui permet de répartir la charge. En cas de défaillance, le systčme redistribue la charge sur un nombre réduit de liaisons. « Les centres de données actuels sont construits autour d'un concept de systčme ŕ deux sockets pour l'ensemble du traitement. Si les choses tiennent dans ce serveur ŕ deux sockets, tout va bien. Mais dčs que l'on sort de ces limites, ce n'est plus aussi efficace », a déclaré M. Mukherjee. « Nous avons finalement conclu que l'architecture elle-męme devait changer et que ce problčme devait ętre résolu », a poursuivi M. Mukherjee. Et selon lui, « la solution devait venir d'une entreprise de silicium, et de proposer un systčme moderne qui permet de réaliser cette répartition de maničre rapide et complčte ».
L'ACF-S assure une commutation et un pontage ŕ plusieurs térabits entre des ressources hétérogčnes de calcul et de mémoire dans une seule puce sans modifier les interfaces physiques, les protocoles ou les couches logicielles qui se trouvent au-dessus des pilotes de périphériques. Il réduit le nombre de dispositifs, les sauts de latence E/S et la consommation d'énergie des dispositifs dans les clusters IA actuels, que ce soit l'énergie consommée par les commutateurs réseau top-of-rack, les NIC RDMA-over-Ethernet, les HCA Infiniband, les commutateurs PCIe/CXL ou la DRAM attachée au processeur. Grâce au pontage de mémoire CXL, il est possible de fournir une mise ŕ l'échelle de la mémoire découplée ou headless ŕ n'importe quel accélérateur, de sorte qu'un seul rack de GPU puisse avoir un accčs direct, ŕ faible latence et sans restriction ŕ la DRAM DDR5 CXL.mem locale avec une capacité de mémoire plus de 50 fois supérieure ŕ la mémoire ŕ grande largeur de bande High-Bandwidth Memory (HBM) native du GPU utilisée sur les GPU. Enfabrica a présenté sa technologie lors de plusieurs conférences technologiques récentes, notamment Hot Chips, AI Summit, AI Hardware & Edge AI Summit et Gestalt IT AI Tech Field Day. Une autre présentation aura lieu dans le cadre de la conférence SuperComputing 2024, qui se tiendra du 17 au 22 novembre ŕ Atlanta. Enfabrica n'a pas indiqué de date de disponibilité de ses produits.










Suivez-nous